Daniel C. Dennett’s Four Competences
A useful idea to understand computational control algorithms.
In From Bacteria to Bach and Back Daniel C. Dennett introduces four grades of competence.
They describe four progressively competent intelligences. Each competence learns through iterative application of trail and error learning.

The four competences are an invaluable idea for understanding computational control algorithms.
They organize computational control algorithms by asymptotic performance and sample efficiency - the least efficient algorithms have lower limits on performance.
What is Competence?
Competence is the ability to act well. It is the ability of an agent to interact with its environment to achieve goals.
Competence can be contrasted with comprehension, which is the ability to understand. Together both form a useful decomposition of intelligence.
Competence allows an agent to do control - to interact with a system and produce a desired outcome.
Evolutionary Learning
Maybe it would be good for hackers to act more like painters, and regularly start over from scratch
Paul Graham
Evolutionary learning is trial and error learning.
It is iterative improvement using a generate, test, select loop:
- generate a population, using information from previous steps
- test the population through interaction with the environment
- select population members of the current generation for the next step
It is the driving force in our universe and is substrate independent. It occurs in biological evolution, business, training neural networks, and personal development.
There is much to learn from evolutionary learning:
- failure at a low-level driving improvement at a higher level
- the effectiveness of iterative improvement
- the need of a dualistic (agent and environment) view for it to work, at odds with the truth of non-duality
These are lessons to explore another time - for now, we are focused on the four grades of competence.
Comparing Competence
There several metrics we can use to compare our intelligent agents.
Asymptotic performance measures how an agent performs given unlimited opportunity to sample experience. It is how good an agent can be in the limit and improves as our agent gains more complex competences.
Sample efficiency measures how much experience an agent needs to achieve a level of performance. This also improves as our agents get more complex. The importance of sample efficiency depends on compute cost. If compute is cheap, you care less about sample efficiency.
Each of the four agents interacts with the same environment. Interacting with the agent allows an agent to generate data through experience. What the agent does with this data determines how much data it needs. The more an agent squeezes out of each interaction, the less data required.
The Four Competences
The four competences are successive applications of evolutionary learning - this means that each agent has all the abilities that the less competent agent had.
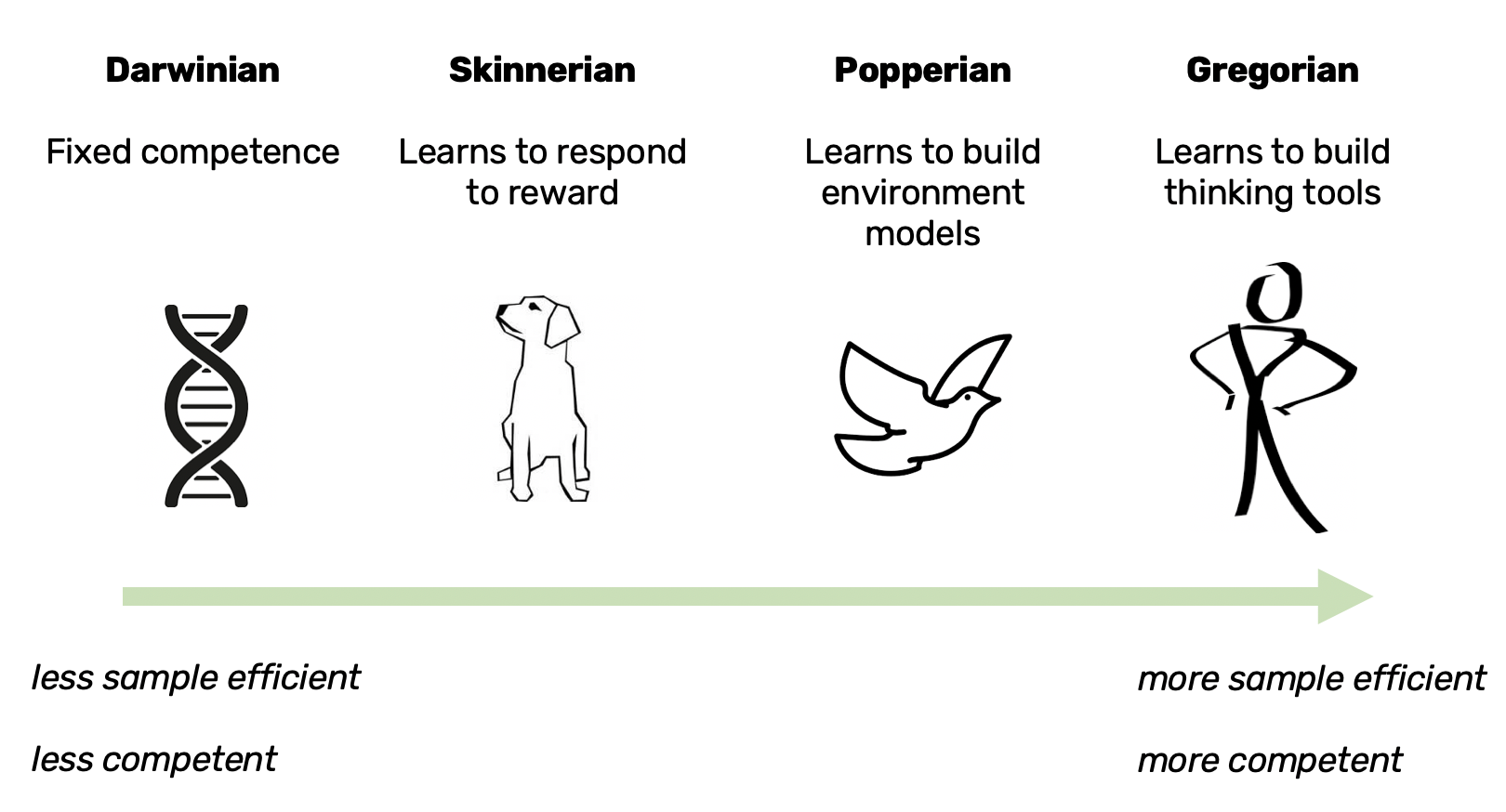
1. Darwinian Competence
The Darwinian agent has pre-designed and fixed competences - it doesn’t improve within it’s lifetime.
Improvement happens globally via selection that aggregates across the agent’s entire lifetime.
Biological examples include bacteria and viruses. Computational examples include CEM, evolutionary algorithms such as CMA-ES or genetic algorithms.
2. Skinnerian Competence
The Skinnerian agent improves its behaviour by learning to responding to reinforcement. It can improve within it’s lifetime by learning how to map states and actions to reward signals, such as food or dopamine.
Biological examples include neurons and dogs. Computational examples include model-free reinforcement learning, such as DQN or Rainbow. The GPT series of language models has Skinnerian competence.
3. Popperian Competence
The Popperian agent learns models of its environment - improvement occurs by offline testing of plans with its environment model.
Biological examples include crows and primates. Computational examples model-based reinforcement learning such as AlphaZero or World Models and classical optimal control.
4. Gregorian Competence
The Gregorian agent builds thinking tools, such as arithmetic, constrained optimization, democracy, and computers. Improvement occurs via systematic exploration and higher-order control of mental searches.
The only biological example we have of a Gregorian intelligence is humans. I do not know of a computational method that builds it’s own thinking tools. Now we have introduced our four agents we can compare them.
Comparing the Four Competences
Darwinian agents improve through selection determined by a single number. For biological evolution, this is how many times an animal has mated.
For computational evolution, this is a fitness, such as average reward per episode. These are both weak learning signals. This accounts for the poor sample efficiency of agents with Darwinian competences.
Compare this with the Skinnerian agent, which can improve both through selection and reinforcement. Being able to respond to reinforcement allows within lifetime learning. It has the ability to learn from the temporal structure of the environment. The Skinnerian agent uses this data to learn functions that predict future rewards.
The Popperian agent can further improve within its lifetime by learning models of its world. Generating data from these models can be used for planning, or to produce low dimensional representations of the environment.
Summary
Daniel C. Dennett’s four grades of competence describe four progressively competent intelligences, that each learn through successive applications of trial and error learning.
It allows understanding of the asymptotic performance and sample efficiency of learning algorithms and highlights two useful dimensions of intelligent agents - what data they use and what they learn from this data.
Of the most competent of our agents, humans are the only biological examples. We have no computational examples.
Thanks for reading!