Warming up with Pipeline Data Engineering Academy
My experience being a part of the Summer Camp - Pipeline’s week long data engineering adventure.
In May 2020 I took part in the Pipeline Summer Camp - the inaugural offering from the Berlin data engineering bootcamp Pipeline Data Engineering Academy.
I’m writing this post as a thank you to Peter & Daniel (the founders of Pipeline). I got lots of value from their Summer Camp (as you’ll see below). Part of the reason for this thank you is to help others benefit from the value that Peter & Daniel are trying to bring to the world.
I know Peter from my time at Data Science Retreat, where he combined business acumen with a genuine care for the success of students. I’ve only met Daniel online, and it was clear from the Summer Camp that his combination of technical expertise, experience and teaching approach will be massively valuable to new data engineers.
It’s an exciting team, and I’m looking forward to seeing Pipeline establish themselves in Berlin - consider me a fan.
What was the Summer Camp?
The Summer Camp was a one week course in data engineering, held online in May 2020, when much of the world’s population was in lockdown.

The effects of corona have been felt worldwide - yet there is opportunity in this crisis. Pipeline have shown already they are capable of seeing opportunity in a crisis.
It’s not easy to teach online - the last few months at [Data Science Retreat] were spent developing a coronavirus strategy for the school, including how to deliver classes online. The course content (mainly lectures over slides) was delivered skilfully and technically relevant. Students all felt comfortable enough to ask questions, which is a sign of a well delivered class.
The course is a great example of a lean approach - a minimum viable product with lots of customer feedback. It’s great to be a part of, and I’m looking forward to seeing Pipeline expand their offering in data engineering education.
The course was delivered remotely via Zoom & Slack - roughly half teaching time, half project work. The goal of the course was simple - build a data engineering product in a week.
You built a data engineering product in a week?
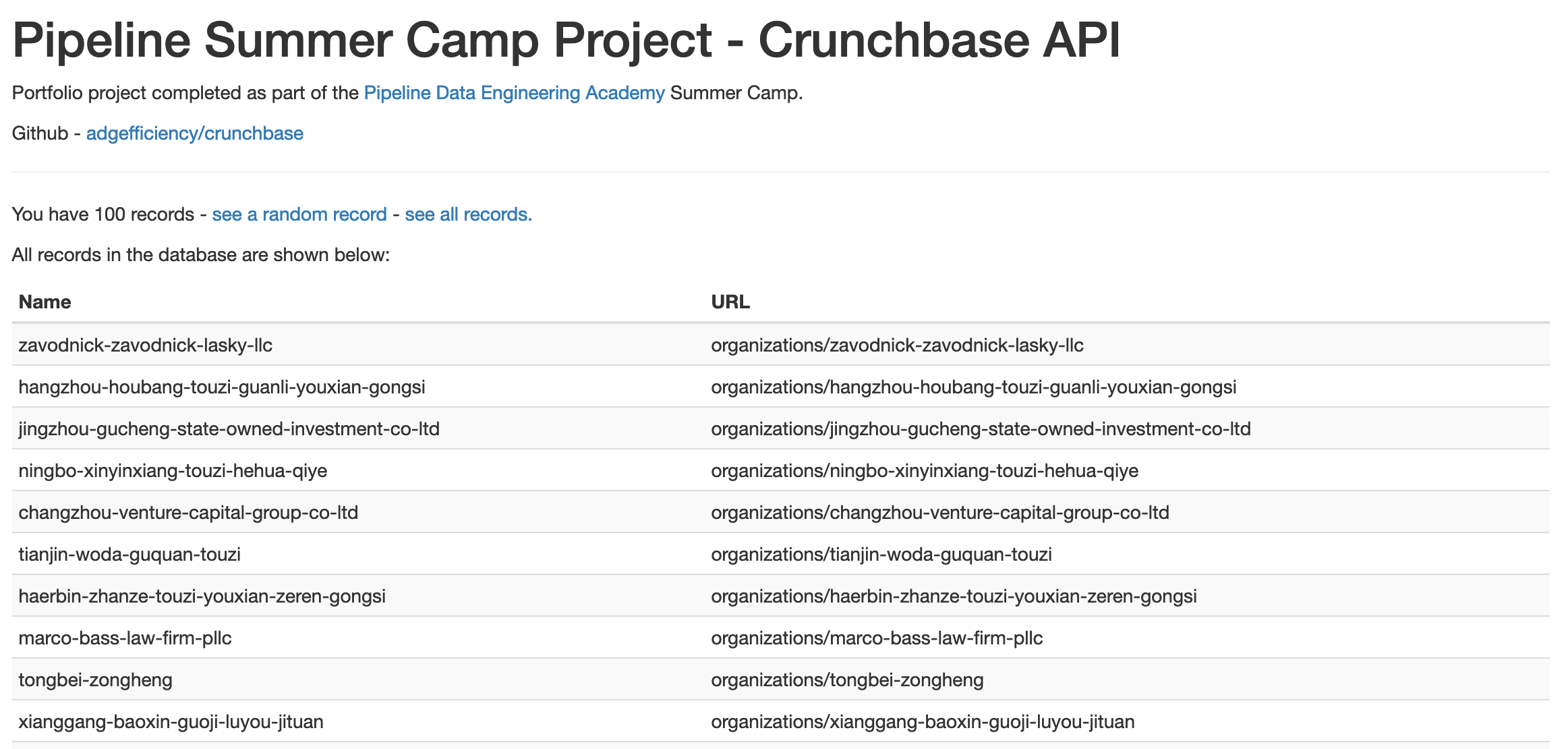
Yes! During the week we had a simple data product running locally, built from:
- API data access with Python
- SQLite
- Flask web server to display data
- Docker (because why not?)
Later on, technical debt was repaid and the app was deployed:
- Makefile
- Jinja & Bootstrap templating
You can see the deployed app on PythonAnywhere - you can also see the source on GitHub. Deploying the app on PythonAnywhere:
As someone who has taught data science for a while, the most impressive thing was the simplicity of the stack. It is very easy when teaching to complicate things for students, or to teach complex tools that confuse more than help.
It can’t be understated the power of leaving after five days with a working product. The value of being able to see and interact with your data is huge, for spotting problems with your data pipeline to showing off to customers (or employers!).
The use of SQLite was a highlight for me - I had no idea how widespread it is (that it is available at /usr/bin/sqlite3, or runs on many mobile phones). Technology that has no setup/install cost is great. SQLite isn’t the best database choice for all problems, but it’s great to know it is a defensible choice for new projects.
Another was the usefulness of Makefiles to build DAGs. I was familiar with the idea of DAGs from Airflow & Tensorflow - it’s great to know that I can do something similar semantically using make & Makefile.
There were a few other tools taught on the course, including Datasette & GitHub Actions - playing with these is on my TODO.
I’ve also been able to use lessons & learnings in other projects such as the climate-news-db. It’s also given me a stack (Python, Flask, SQLite, PythonAnywhere, Jinja & Bootstrap) that allows full stack, agile data science.
What can you learn in a week anyway?
Alongside the project work was more traditional tutorial content. The technical content was opinionated (without being religious), and full of useful perspectives on data engineering:
- access to data
- connect things together
get / load, store, deploy
A particularly useful insight was enriching data to make it valuable to the business - including a brilliant example of converting a UNIX timestamp to data with semantic meaning and value:
- UNIX epoch time
- datetime (5th Jan 2020 etc)
- thursday (calculable)
- the fall of the Berlin wall (resolvable with enricher)
There was also a strong emphasis on being pragmatic, avoiding absolutes and realizing there isn’t a one size fits all solution.
- there is no good place to be on the cloud, all have downsides, best stragety = be prepared
- three types of use of data
- analytical (what will happen)
- forensic (what happened)
- monitoring (what is happening)
- 9/10 problems occur with external data
- filter then join!
- be defensive
- err on the side of understandable
- thinking about separation of concerns / dependency in how you structure data on disk
Where to go next
If you are someone considering transitioning into a data (especially data engineering), consider data engineering with Pipeline Data Engineering Academy.
Thanks for reading!