AI, Machine Learning and Deep Learning
What’s the difference between artificial intelligence, machine learning and deep learning?
When we raise money it’s AI, when we hire it’s machine learning, and when we do the work it’s logistic regression - JUAN MIGUEL LAVISTA
Artificial intelligence has seen outstanding progress in the last ten years. The state of the art on a wide range of challenging problems are powered by a specific branch of artificial intelligence - machine learning.
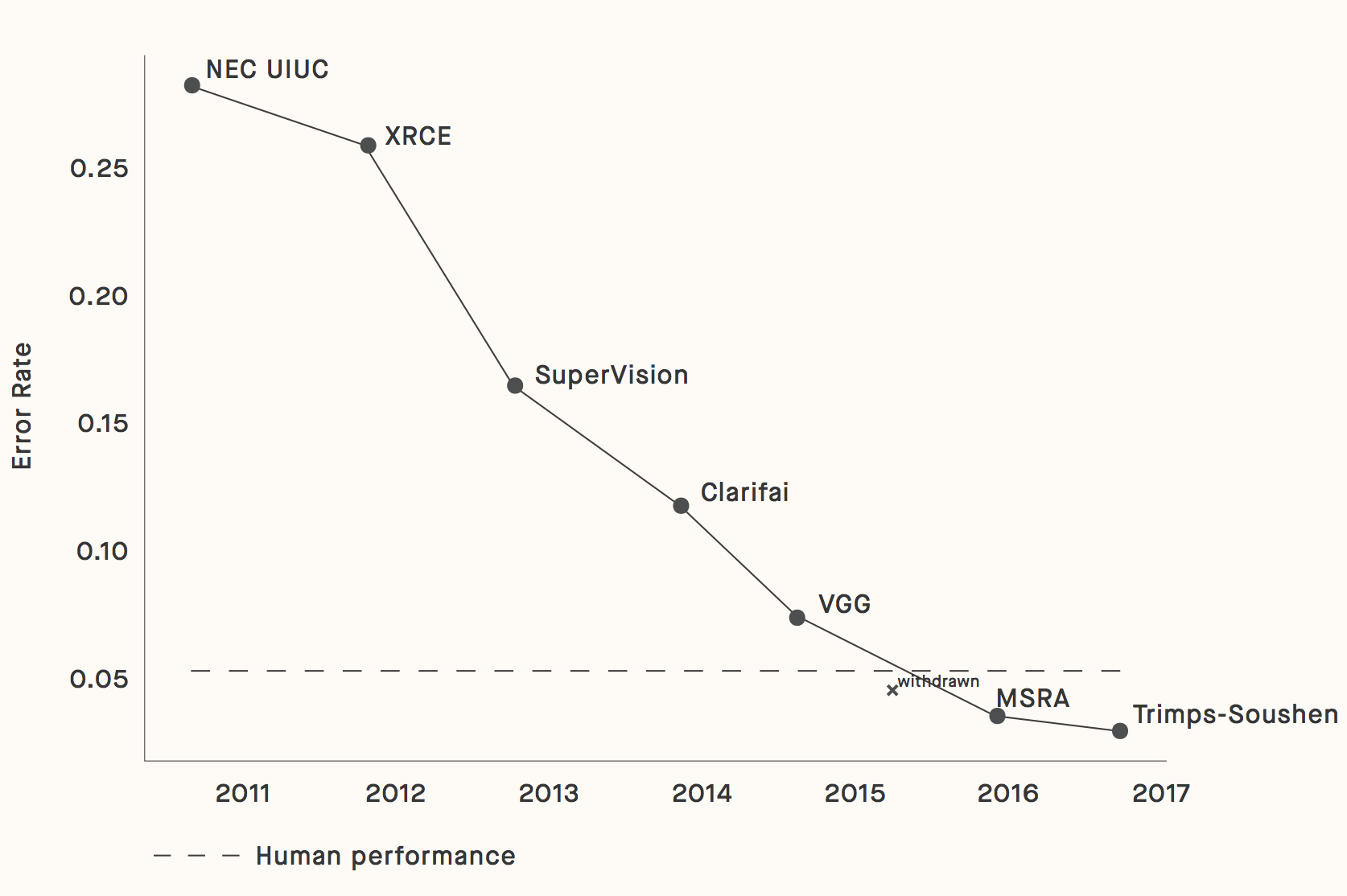
Progress on the ImageNet benchmark, a popular test of computer vision model performance, shows the dramatic improvements since 2011:
charlatan - noun - a person falsely claiming to have a special knowledge or skill
Yet alongside this real progress inevitably come fakes, scammers and charlatans. How can we spot these people? How can we make sure we don’t turn into one?
One hint of machine learning charlatan is using technical terms like artificial intelligence, machine learning or deep learning interchangeably - they are not the same thing!
Mixing up these terms is a sign that someone is not experienced - or even worse, that they are intentionally trying to mislead you (commonly to get you to work at or invest in their startup).
Avoid this by understanding well the difference between artificial intelligence, machine learning and deep learning. This post will clarify these three foundational concepts - artificial intelligence, machine learning and deep learning - what they are and how they relate to each other.
Let’s go!
Outline
The section on Artificial Intelligence will answer:
- what is AI?
- what is intelligence?
- the difference between competence and comprehension,
- the difference between rules & learning.
-
The section on Machine Learning will answer:
- what is machine learning?
- why is modern machine learning working so well?
- what are the three ingredients of machine learning?
- what are the three branches of machine learning?
- how does machine learning learn?
- what are machine learning models doing?
The section on Deep Learning will answer:
- what is deep learning?
- what is a neural network?
- what tasks does deep learning perform well on?
Artificial Intelligence
What is AI?
Artificial Intelligence (AI) is the field of creating problem solving machines - a dream of humanity since antiquity.
The myth of Talos, a giant bronze robot protecting the harbour of ancient Crete, is about an intelligent machine. It solves one of our most ancient needs - that of safety.

Much of the foundations of modern, digital AI were laid by Alan Turing - including a proof that any form of computation could be described in digital form - the Turing Machine.
Incredibly, this theory was developed before digital computers could be built.

The second half of the 20th century saw the rise of the digital computer, and with it the first attempts to create electronic & digital brains.

These digital computers now from the heart of modern artificial intelligence. AI can be either physical hardware (such as a robot) or software (such as a computer program) or a combination of both.
The artificial term in AI is simple to understand - anything made by humans. Intelligence however, is harder to define.
What is intelligence?
Intelligence is one of those concepts you know when you see it but lack simple, formal definitions.
It is useful to examine concepts like these from a few different perspectives (we will do the same for machine learning later):
- competence versus comprehension,
- rules versus learning,
- Claude Shannon’s goals of AI,
- Dan Simon’s five characteristics of intelligence.
Competence versus comprehension
The first perspective we will look at is a decomposition of intelligence into two concepts - competence and comprehension:
- competence - the ability to perform a task well,
- comprehension - the ability to understand a task.
Take the example of operating an elevator. Historically this was done by people, who had both competence (to operate the elevator safely & efficiently) and comprehension (they understood what an elevator was, what their role was, who the passengers were etc).

Now elevators are operated by machines - rule based, automated systems. These systems are competent (more competent than human operators), but lack comprehension about the task they perform. We couldn’t say that an elevator control system understands what it is doing.
The machine elevator operator is a rule based system - human designed but operated without human input. If we consider competence alone to be sufficient for intelligence, then many machines we live and work with today can be considered intelligent - including the elevator.
Many energy industry professionals will be familiar with the programmable logic controller (PLC) - a simple device responsible for controlling over 95% of industrial systems on the planet. These systems are competent - but are they intelligent?
Given a broader definition of intelligence, AI has been here for a while, in the form of rule based automation.
Are rules, defined and executed in a computer program, artificial intelligence?
But rule based automation is not the only approach to creating intelligent systems.
In order to understand the relationship between AI and machine learning, we will introduce our second perspective of AI - that of rule based versus learning systems.
Rules versus learning
Our ability to learn is a key component of human intelligence. This ability to learn is supercharged by our ability to learn not only from our experience but from the experience of others.
Giving machines the ability to learn for themselves contrasts directly with the rule based approach to AI.
A defining feature of rule based systems is that they are human designed - human programmers need design them. The dependency on human design can make rule based systems expensive, and can limit performance to human levels. The benefit of relying on human design is removing a dependency on data - rules can be constructed without data.
For artificial systems, learning removes the dependency on the human programmer and introduces a dependency on experience - also known as data. A machine that can learn can essentially program itself, and even reach superhuman levels of performance. You do however need examples to learn from.
That isn’t to say that learning is always better than a rule based system. If you can solve a business problem (such as operating an elevator) with rules, you should do so.
Rules can also be explained and interpreted - systems that have learnt for themselves can often not do either.
Case study - rules vs. learning - DeepBlue vs. AlphaGo
To finish our look at AI, we will compare two landmark achievements that occurred 20 years apart - DeepBlue and AlphaGo - the first superhuman computers to play chess and Go.
Chess playing computers were dreamt of from the earliest days of computing - both Alan Turing and Claude Shannon created chess computer programs.
The challenge of creating a superhuman chess program (one that could beat the best humanity had to offer) was overcome in 1996 with DeepBlue. DeepBlue was a chess playing computer built by IBM, that beat the world chess champion Gary Kasparov by a score of 4-2 in 1996.

While chess had fallen, Go remained a challenge. The search space of possible positions in Go is vast - combined with a more difficult position evaluation problem the DeepBlue approach did not scale to Go.
AlphaGo is a Go playing computer built by DeepMind, that beat Lee Sedol, a ranked 9-dan Go player 4-1. It learnt to play Go through a combination of self play, resnets, value functions, a policy and Monte Carlo Tree Search.
For me, AlphaGo is the crowning achievement of the modern deep learning era. An achievement that occurred almost ten years before experts thought it was possible, AlphaGo conquered the last great challenge of board game playing computers.

Both DeepBlue and AlphaGo are outstanding achievements. One of the key difference between the two approaches is the use of human designed rules versus the use of learning.
DeepBlue was a rule based system - handcrafted by human programmers and chess experts. DeepBlue relied on human designed databases of openings & endgames.
AlphaGo was a learning system - a machine learning algorithm that learnt the game of Go from data & self play. While the algorithm of AlphaGo was human designed, humans had no input in guiding how AlphaGo learnt to play Go, beyond curation of data to start the learning process.
Later versions of AlphaGo (such as AlphaZero), made no use of human data - learning only from self play.
Goals versus learning
In the excellent book Mind at Play we get a glimpse at Claude Shannon’s goals of AI:
- how can we give computers a better sensory knowledge of the real world?
- can they better tell us what they know?
- can we get them to act upon the real world?
Dan Simon’s five characteristics of intelligence
In the textbook Evolutionary Algorithms, Dan Simon shares characteristics he wants to build into evolutionary algorithms:
- adaptation - ability to respond to a changing environment,
- randomness - needed for many effective adversarial strategies,
- communication - emerges in populations, communicate our successes and failures.
- feedback - adaptation and learning,
- exploration - balanced with exploitation.
Summary - Artificial Intelligence
Important takeaways from this section are:
- artificial intelligence is the field of creating intelligent machines that can solve problems,
- intelligence is hard to define,
- human designed rules and learning are two different approaches to AI.
Machine Learning
What is machine learning?
Machine learning is the biggest advance in how we can do engineering since the scientific method - Steve Juvertson
Machine learning is the family of AI approaches where machines learn from data. Machine learning has been the most effective AI approach in the last ten years.
Three ingredients of machine learning
Machine learning has three ingredients - data, compute and an algorithm:
machine learning = data + compute + algorithm
We can use this equation to explain why modern machine learning is working so well.
The rise of the internet has led to a vast increase in how much data is being generated - from sensors on wind turbines to photos on your smart phone, we now generate and collect more data than ever.
Alongside this our ability to perform more computation at cheaper prices continues to improve. For machine learning, a key innovation was repurposing graphical processing units (GPUs), originally designed for gaming, to train neural networks.
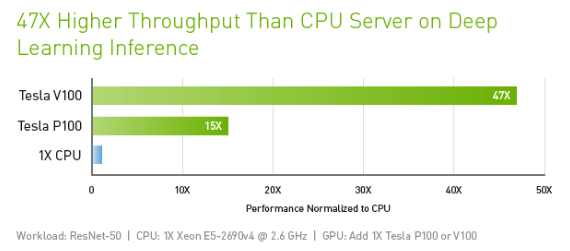
Invention continues with machine learning hardware, with the development of special purpose hardware built for machine learning, such as the tensor processing unit (TPU).
Finally, innovation has continued on the algorithm side, with researchers developing and improving the programs and models used in machine learning.
Compute and algorithms are widely available - massive amounts of compute can be purchased on the cloud, and almost all machine learning research and tooling is freely available on arxiv or GitHub.
The combination of these three factors - data, compute & algorithms - are driving the performance of modern machine learning and AI.
I have data - how can I use machine learning with it?
How we can apply machine learning to a dataset depends on multiple factors. Some of the most important are:
- what kind of data you have,
- the amount of data you have,
- how clean the data is,
- how stationary the data is,
- if the data has seasonality,
- if the data has a trend.
Because data is so important to machine learning, we will begin our look at machine learning with a case study on the kind of data an energy retailer can collect, and how we can apply machine learning to it.
Case Study - Energy Customer Data
Throughout this section we will use a case study of a fictional energy company EnergyCo to help explain how machine learning can be used on energy industry datasets and problems.
Three common types of data generated in the energy industry are:
- tabular data,
- time series data,
- decision data.
This case study looks at how EnergyCo generates these three kinds of data.
Tabular data
Tabular data will be familiar to anyone who has spent time in Excel - data organized into rows and columns. Each row represents a sample of data, each column represents a feature or characteristic of each sample.
An example of tabular data EnergyCo would collect would be where the customer lives or when they signed up:
| Name | Address | Contract Start |
|---|---|---|
| Bill | 123 Fake Street | 2016-01-01 |
| Jane | 321 Real Lane | 2016-01-15 |
Time series data
Time series data looks similar to tabular data - but now there a temporal (time) component to the data. This temporal component gives the data an ordinal structure - each sample is linked by time to a sample that occurred before and after it.
An example of time series data would be customer monthly energy consumption:
| Month | Name | Consumption |
|---|---|---|
| 2016-01 | Bill | 116.8 |
| 2016-02 | Bill | 204.3 |
| 2016-01 | Jane | 50.4 |
| 2016-02 | Jane | 311.0 |
Decision data
Decision data involves action - something was chosen (either by a human or machine) that changed the data seen afterwards.
An example of decision data would be the data collected by EnergyCo’s customer support team:
| Timestamp | Customer Name | Reason for call | Action |
|---|---|---|---|
| 2016-01-03 | Bill | Invoice too high | Reissue invoice |
| 2016-02-15 | Jane | Invoice late | Update customer address |
Now that we have examples of what kind of data EnergyCo collects, we can look at how to apply machine learning to these datasets. To do this we first need to outline three approaches to AI.
The three branches of machine learning
Machine learning can be separated into three branches, based on the signal available to the learner:
- supervised learning
- unsupervised learning
- reinforcement learning
These three branches correspond to the tasks commonly done by machine learning:
- predicting with supervised learning
- generating data with unsupervised learning
- making decisions with reinforcement learning
Below we will look at how each of these three branches relate to data collected by EnergyCo.
Branch 1 - Supervised learning
The first branch is supervised learning, where labelled training data used to learn how to predict the labels of unseen data.
Examples include time series forecasting, computer vision and language translation. For our EnergyCo dataset, supervised learning would predict the monthly consumption of our customers.
For the dataset below we have labels for all our samples except the last one:
| Month | Name | Consumption | Predicted Consumption |
|---|---|---|---|
| 2016-01 | Bill | 116.8 | 115.4 |
| 2016-02 | Bill | 204.3 | 202.0 |
| 2016-03 | Bill | ??? | 250.6 |
| 2016-01 | Jane | 50.4 | 45.9 |
| 2016-02 | Jane | 311.0 | 305.1 |
| 2016-03 | Jane | ??? | 315.9 |
Branch 2 - Unsupervised learning
The second branch is unsupervised learning, where new data is generated without the supervision of labels.
An example of applying unsupervised learning to our EnergyCo dataset would be clustering - grouping customers based on structure learnt in the data:
| Name | Address | Contract Start | Cluster |
|---|---|---|---|
| Bill | 123 Fake Street | 2016-01-01 | 1 |
| Jane | 321 Real Lane | 2016-01-15 | 2 |
| Jill | 123 Actual Place | 2016-01-20 | 2 |
Our clustering algorithm has determined that that Jane & Jill belong to the same cluster - indicating that these customers are similar.
Branch 3 - Reinforcement learning
Reinforcement learning is the branch of machine learning associated with decision making. In reinforcement learning the machine learns to select actions with the supervision of a scalar reward signal.
For our EnergyCo dataset, reinforcement learning would be able to select the best action that our customer service team should take:
| Timestamp | Customer Name | Reason for call | Taken action | Best Action |
|---|---|---|---|---|
| 2016-01-03 | Bill | Invoice too high | Reissue invoice | Recalculate balance |
| 2016-02-15 | Jane | Invoice late | Update customer address | Check credit history |
How does machine learning work?
Above we have looked at examples of data generated in the energy industry, and how the three branches of machine learning (supervised, unsupervised and reinforcement) can be used with these datasets - the what of machine learning.
Now we will look at the how - how does machine learning actually work?
Learning by trial and error from data
Fundamentally, machine learning algorithms learn through trial and error. It’s nothing more complicated than trying something, seeing how wrong you were, using the error to improve and trying again.
Models are often trained in successive steps, each time learning how to perform better by learning from it’s mistakes:
- get some data
- make predictions on that data
- compare your predictions with the target to create an error signal
- use the error signal to improve
- repeat steps 2-5
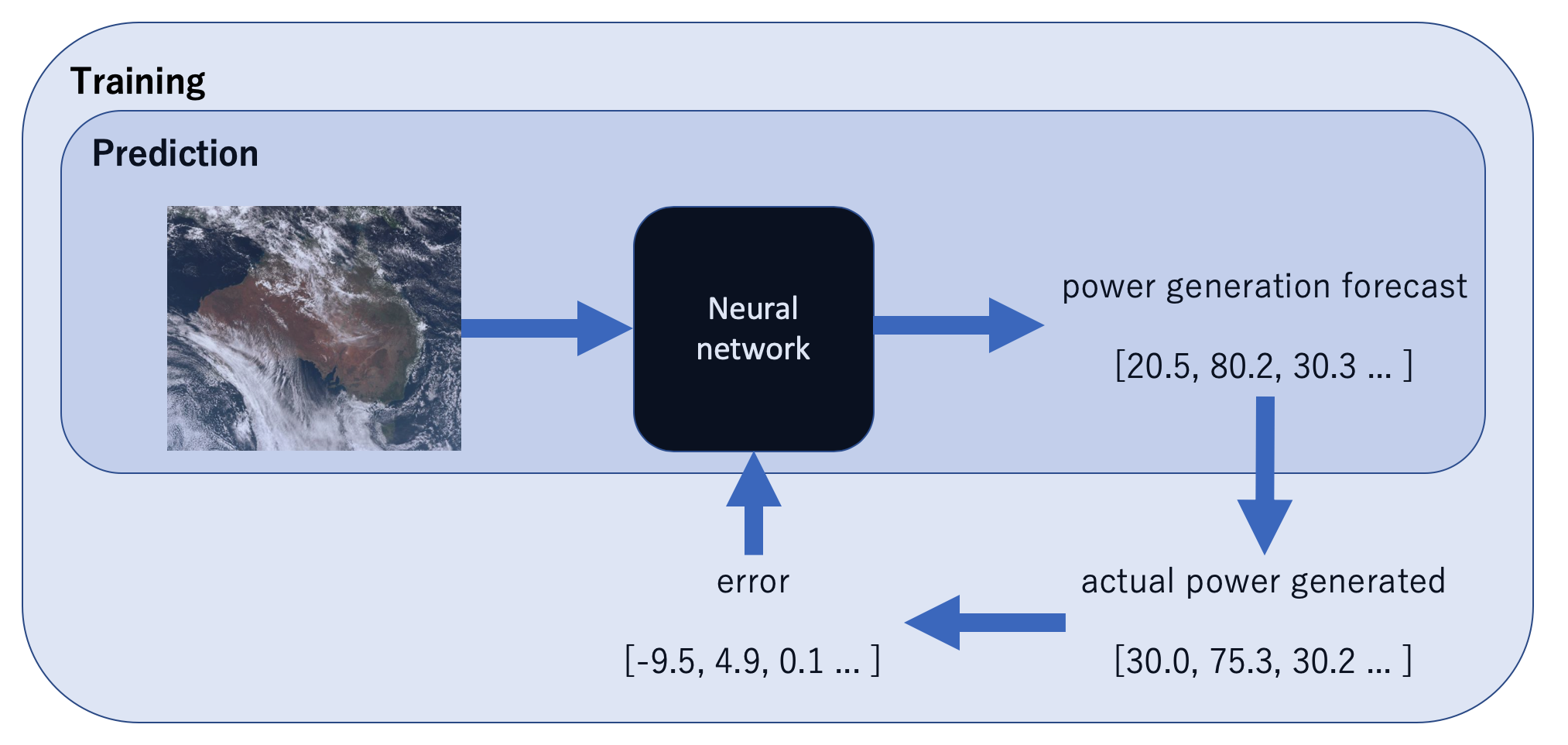
It’s really that simple!
Testing on unseen data
All of this learning occurs on training data - data that the model can learn from. A second kind of data is test data - data we use to evaluate performance
All data is a combination of signal and noise - a model can perform well on training data arbitrarily well by fitting to this noise, or memorizing it. Overcoming overfitting is perhaps the central challenge in machine learning.
To combat overfitting, the performance of a model is measured on unseen data, known as test or holdout data. Models that are able to perform on unseen data are said to have generalized - to have learnt meaningful patterns that will hold on data in the future.
What are machine learning models doing?
Above we looked at how machine learning works:
- learn by trial and error on training data
- test performance on unseen data
We will finish our look at machine learning with the what - a few of high level perspectives on what machine learning is doing.
Pattern recognition
All machine learning involves pattern recognition. The patterns being learnt in the three branches are:
- supervised learning is learning how the features relate to the target
- unsupervised learning is learning patterns of the features alone
- reinforcement learning learns the pattern of how actions lead to rewards
As mentioned above in our section on testing, it’s important that the patterns being learnt are signal - not noise.
Programming without programming
A second useful perspective on machine learning is programming without programming - also known as Software 2.0.
Machine learning can be seen as a fundamental change in how we do programming - instead of having to explicitly program behaviour, programming is done by giving a machine data - examples of the patterns we want to learn or the behaviour we want to achieve.
Dimensionality reduction
Intuition in n-dimensions isn’t worth a dam - GEORGE DANZIG
Reducing a high dimensional sample of data to a lower dimension is a fundamental process in machine learning.
Low dimensional representations of high dimensional data are more valuable than high dimensional representations - because decisions are easier to make in low dimensional spaces.
Function approximation
The final perspective on machine learning is function approximation.
A function is simple - input goes in and output comes out. The reason this is a useful perspective on machine learning is that functions are what we learn in machine learning.
Often these functions are complex, such as:
- image pixels to text
- weather data to wind turbine power output
- predicting the next word in a sentence
Summary - Machine Learning
Important takeaways from our look at machine learning are:
- machine learning has three ingredients - data, compute & algorithms
- machine learning has three branches - supervised, unsupervised and reinforcement
- machine learning works by learning from training data and testing on unseen test data
- pattern recognition, programming without programming and dimensionality reduction are three useful paradigms for what machine learning is doing
Deep Learning
What is deep learning?
Deep learning is the family of machine learning models known as artificial neural networks. Artificial neural networks are inspired by the biological neural networks in our brains.
Artificial neural networks are simple approximations of their biological counterparts. Yet even though they are simpler than the brain, artificial neural networks are still able to achieve superhuman performance on a wide variety of tasks.
The fundamental building block of a neural network is the artificial neuron. Many of these neurons together form a layer - these layers can then be stacked in a sequence. This is where the deep in deep learning comes from - multiple layers of neurons connected to each other.
Further reading - An Animated Guide to Deep Learning.
Why is deep learning important?
The last ten years have been the deep learning era of AI - deep learning has driven much of the outstanding progress and hype across a wide range of challenging machine learning problems.
Three areas of machine learning revolutionized by deep learning are computer vision, natural language processing and reinforcement learning.
Deep learning powered computer vision is the most advanced of the three, with the state of the art on tasks such as object detection powered by convolutional neural networks. Computer vision
Deep learning powered natural language processing has seen the rise of massive language models such as GPT3 - able to convert natural language into code. These are trained as unsupervised models - learning to predict the next word in massive datasets scraped from the internet.
{kind=link}
Deep learning has also had a massive impact on reinforcement learning, using neural networks as powerful function approximators to select and value actions.
How does deep learning fit with the three branches of machine learning?
Deep learning offers a class of functions - neural networks. A neural network is like any other function - it takes some input and produces an output.
These neural networks can be used as components of any of our three machine learning branches, to create:
- deep supervised learning
- deep unsupervised learning
- deep reinforcement learning
The ability of neural networks to be used on a wide variety of machine learning tasks is one reason why deep learning has been so important - an ability to generalize not only across test & train data but across tasks as well.
What tasks does deep learning perform well on?
The major benefit of deep learning is that performance scales with data - something that isn’t true of classical machine learning.
This ability to scale with data is also a weakness - deep learning requires a lot of data to work.
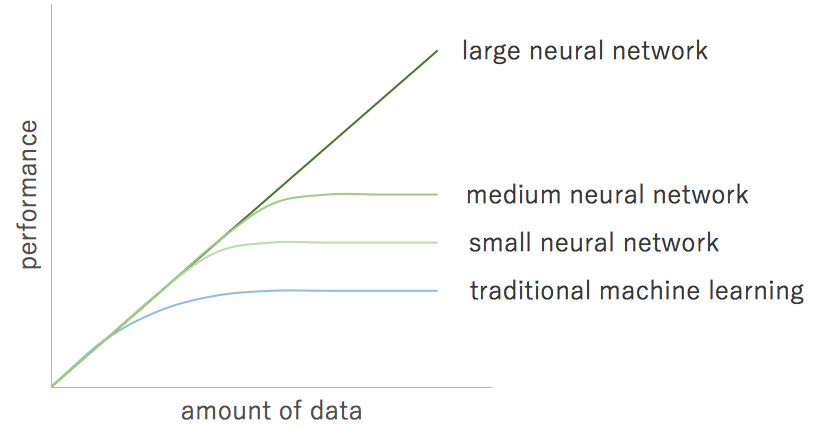
Deep neural networks are able to learn from massive amounts of data - adapted from ‘AI is the New Electricity’ (Andrew Ng)
While deep learning is undeniably amazing, it is not state of the art on all tasks.
On a wide range of tabular data problems, classical machine learning (namely gradient boosted decision trees) reign supreme. Many business problems are tabular data problems - making deep learning less useful in many industries than the hype suggests.
Deep learning excels when there is structure in data - data such as images, audio or text all have structure that neural networks can be built to exploit:
- images = spatial structure - height, width and depth
- audio = temporal structure
- text = syntactic or grammatical structure

Tabular data has very little structure - often it is presented to a network as a flat array, with little structure to be able to learn from.
Summary - Deep Learning
Key takeaways from this section on deep learning are:
- deep learning is the branch of machine learning concerned with building artificial neural networks,
- the deep in deep learning comes from many layers of neurons feeding into each other,
- neural networks can be used with supervised, unsupervised or reinforcement learning as function approximators.
Summary
And that’s it! I hope this post has been useful to help you to learn about these challenging concepts of artificial intelligence, machine learning and deep learning. These are
The three most important takeaways from this post are:
- artificial intelligence = creating intelligent machines that can solve problems
- machine learning = a branch of AI, where machines learn from data
- deep learning = branch of machine learning, using neural networks
Thanks for reading!
If you enjoyed this post, make sure to check out my post on A Guide to Deep Learning.