energy-py - reinforcement learning for energy systems
An introduction to the open source energy focused reinforcement learning library energy-py.
energy-py provides reinforcement learning agents, environments and tools to run experiments on energy systems - take a look at the project on GitHub. This post introduces the motivations for the project.
How do we control energy systems today?
Rules don’t get better over time, but AI does - Dan Fuenffinger
A common way to control an energy system is using a heuristic - a simple rule often based on operator experience. An example is a rule I encountered in industry - to run a biomass boiler in preference to a gas engine on a district heating site.
The economics of running a biomass boiler versus gas engine depend on (among other things) gas, biomass and electricity prices. When gas prices were driven down by shale oil, the most cost efficient asset often became the gas engine.
This exposes a flaw in using a heuristic - the heuristic can’t deal with exogenous variables changing.
Why do we need something better?
Holding temperature down under 2°C — the widely agreed upon target — would require an utterly unprecedented level of global mobilization and coordination, sustained over decades - Vox
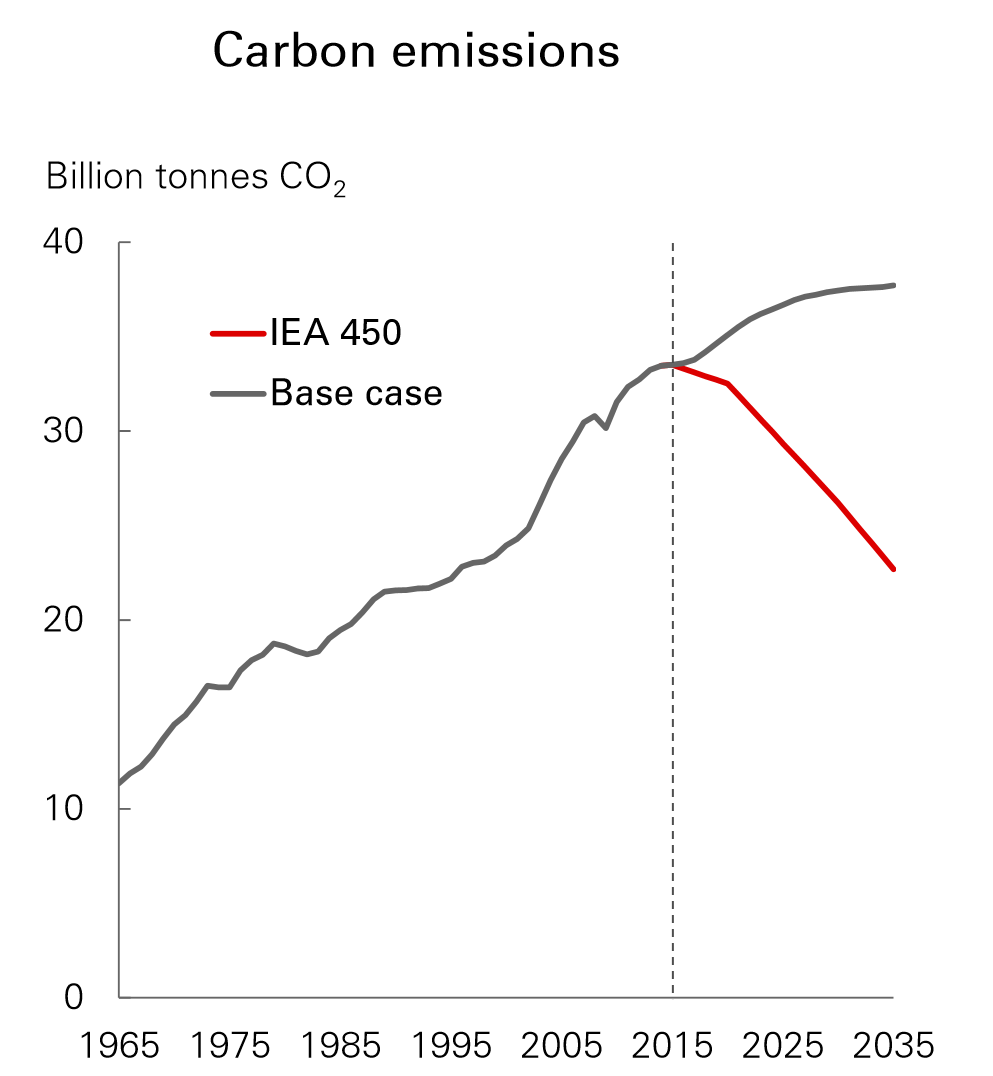
The primary driver behind improving the control of energy systems should be climate - in reality it will be cost. The figure below shows just how far away reality climate we were in 2015. Since 2015 emissions have increased from 35.6 GtC to 37.1 GtC in 2018.
The clean energy transition makes the control problem harder, by introducing uncertainty on the generation side (from grid scale wind and solar) and the demand side (from low voltage solar). Intelligent operation of these systems can help to deal with this uncertainty.
What might that better algorithm be?
A more advanced approach takes external variables such as price and weather into account. These can be used with a simulation model of the energy system combined with a control algorithm such as an evolutionary method, a linear quadratic regulator (from optimal control) or a reinforcement learning agent.
There is only one universal approach here - the simpler the model, the better. If you can model the system as linear, mixed integer linear programming is an excellent choice. Cross entropy method is another first-rate algorithm that should be a baseline for more complex models. If a simple heuristic captures most of the value, then perhaps the cost of a more complex algorithm isn’t justified.
Which algorithm you use depends on (among other things) how stochastic key variables such as gas or electricity prices are, the dependence on external variables such as temperature or humidity and the ability to simulate. All of these change which algorithm should be used.
What is reinforcement learning?
Reinforcement learning is a computational approach to learning through action. It’s been used successfully to solve grand challenges in AI and to optimize the cooling of data centres. It is a framework for learning that we can all relate to - trial and error learning.

Modern reinforcement learning uses deep neural networks to approximate value functions and policies. The outstanding achievement is AlphaGo/AlphaZero - achieved ten years ahead of expert expectations.
If you are interested reading more about reinforcement learning, check out my personal collection of rl-resources.
Why reinforcement learning in energy?
Reinforcement learning offers the potential for a single algorithm to generalize across different problems. It also allows agents to learn non-linear patterns using deep neural networks.
Energy offers reinforcement learning two strong reward signals - cost and carbon intensity. A lack of a reward signal can limit the applicability of reinforcement learning.
Energy also offers an abundance of simulators. A weakness of modern reinforcement learning is sample inefficiency, meaning that simulation is required for learning. In situations where a simulator isn’t available, a lack of historical data also means that no environment model can be learnt.
Using reinforcement learning to control energy systems is already a reality in Google’s data centres. As the energy industry digitizes the opportunities for using reinforcement learning will increase.
The digitization work required in energy is still significant. Energy is well behind consumer technology companies in quantity and quality of data. Many sites have collected no historical data, limiting the approaches that can be taken.
Why not AI in energy?
I’m careful to never talk about artificial intelligence. What I want from machine learning is narrow but generalizable machine learning. Artificial intelligence involves many more layers, many of which haven’t been coded yet, and almost all of which I will never grasp.
My goal is to develop a suite of solutions to energy problems. My hope is that narrow machine learning (or even simpler models) can reduce carbon emissions. This has nothing to do with artificial intelligence.
Introduction to energy-py
energy-py has a high level API to run a specific run of an experiment from a yaml config file:
$ energypy-experiment energypy/examples/example_config.yaml battery
An example config file (energypy/examples/example_config.yaml):
expt:
name: example
battery: &defaults
total_steps: 10000
env:
env_id: battery
dataset: example
agent:
agent_id: random
The low level API will be familiar to anyone who has used gym before:
import energypy
env = energypy.make_env(
env_id='battery',
dataset=example,
episode_length=288,
power=2
)
agent = energypy.make_agent(
agent_id='dqn',
env=env,
total_steps=10000
)
while not done:
action = agent.act(observation)
next_observation, reward, done, info = env.step(action)
training_info = agent.learn()
observation = next_observation
Further reading
2016 - DeepMind AI Reduces Google Data Centre Cooling Bill by 40%
2018 - Safety-first AI for autonomous data centre cooling and industrial control
2018 - Machine learning can boost the value of wind energy
DQN debugging using Open AI gym Cartpole
DDQN hyperparameter tuning using Open AI gym Cartpole
Solving Open AI gym Cartpole using DQN
Thanks for reading!